Right now the majority of detections for identity attacks rely on web proxy telemetry. Here’s why the browser can be a better alternative.
Right now the majority of detections for identity attacks rely on web proxy telemetry. Here’s why the browser can be a better alternative.
User web activity can be a rich source of attack detection data. To this end, most organizations today ingest some form of network traffic data for security monitoring purposes.
Typically, network traffic data is gathered by analyzing web proxy and/or DNS logs. But, we regularly speak to organizations that are frustrated with the challenge of piecing together web traffic data, without understanding the opportunity presented by the alternatives.
Even with proxies that can terminate TLS-encrypted datastreams, it’s difficult for even expert security teams to collect and analyze any meaningful data from web proxy logs. While the kind of data needed might be technically possible to extract, the process of reconstructing proxy data to analyze the specific data points that you really need, at scale, is prohibitively complicated.
The old “needle in a haystack” adage is very apt here! Rather than trying to piece together half-broken data – overlaying noisy proxy logs with other sources such as app and IdP telemetry – we think that the browser presents a much simpler way of analyzing relevant data points, particularly when it comes to identity attacks.
Before we get on to detection opportunities in the browser, let’s take a deeper look at the web proxy situation.
Detection based on web proxy – how does it work and what are the limitations?
Web proxies generate common data points that can be used for threat detection, particularly when looking for indicators of an endpoint compromise. They work by inspecting network traffic to and from the endpoint, which includes web activity in the browser.
The classic use case would be inspecting traffic from an endpoint to networked servers and devices, either on the local network or over the internet (e.g. via VPN), to detect signs of suspicious/malicious behavior from the device (indicating a potential compromise). Data is then shipped to a central proxy server where it can be analyzed for indicators of malicious activity.
The traditional proxy setup has a number of limitations:
The proxy needs to be in a position to intercept traffic. It may only be active when a user is in the office, on a VPN and/or for external web traffic only. It might not work if a user is on their home or other other Wi-Fi – e.g. when working from Starbucks, or visiting a customer site, which isn’t an ideal setup in the era of remote working.
Most web traffic is protected by TLS – so a proxy has to decrypt this to inspect what’s inside. At the very least you’re going to need to deploy a CA cert to every endpoint. But, some websites use things like certificate pinning or other SSL-enforcement controls to straight up prevent this. Unless you’re doing TLS-termination at scale with a COTS solution, then the ability to do proxy-based monitoring is seriously limited.
Proxies under the hood
Let’s pop the hood and take a look at the data you can collect using a web proxy that is useful for threat detection.
Typically, you’re looking at data points such as domain names or IP addresses. If the proxy is terminating TLS, you might also have web URLs, the type of web content accessed, and other HTTP-level metadata. Higher level data like file uploads/downloads can sometimes be reconstructed when using very vanilla methods. More advanced proxies might run or open downloaded files in a sandbox for dynamic analysis to identify potentially malicious properties, which has given rise to techniques like HTML smuggling to hide these file downloads from advanced proxies.
In practice this means that you might see that an endpoint at IP address X accessed google.com. If it’s an authenticated proxy, you might see the user of the endpoint as well. Using this data, it’s possible to see which endpoint’s owner accessed the web domain, but not the identity/account they used, or whether they actually logged in at all. So for the majority of in-house proxy setups not doing TLS-termination… that’s it. Even then, without decrypting TLS you can’t be sure you’re seeing the actual/final domain because of technologies like domain fronting that are commonly implemented in modern CDNs.
With TLS termination, it’s possible to see a lot more by inspecting/unpacking the HTTP data. At this point there are two possible approaches: Manual analysis after the fact, or automated analysis on the fly. Unfortunately, there are problems with both options.
There is too much HTTP data to store and manually analyze everything: Usually, organizations limit the data being stored to specific metadata as opposed to trying to store everything (terabytes of data per day), which would be impossibly expensive to store (and also to build the server infrastructure required to index and search it – effectively a mini-datacenter). Not to mention that storing detailed HTTP body data presents a significant security risk, as it includes valid session tokens/cookies for all your identities…
Each web app is custom, making automated analysis (virtually) impossible: Proxy-based solutions have to reconstruct the data after TLS encryption. HTTP data is usually stored in large application JSON/XML objects or even in totally custom encoding – per each app. This means that complex, custom code is required per each app to be able to perform automated analysis. When businesses today are using hundreds of apps on average, automating this process is not feasible as it requires constant reverse engineering of every web app.
So what does this mean? Well, even organizations with a TLS-terminating proxy are limited to manual analysis of select metadata after-the-fact, which massively reduces its utility. You could sink a day or more’s analysis into gathering a small amount of useful data, for example whether a URL was accessed, but not necessarily which device/user, or what account/creds were used to log in). This means you’re probably going to use proxy data to aid in the investigation of a known incident rather than anything proactive.
It might be theoretically possible to sift through decrypted HTTP data to identify and correlate identities and actions, effectively reconstructing web pages from the network traffic automatically and on the fly (in the same way that it’s theoretically possible to remove my head and transplant it onto your body), but is it practical or reasonable for most organizations to do this? No.
Browser data: a better alternative?
One way of overcoming some of the limitations of the classic web proxy setup is to use a browser-based solution. It’s much easier to collect data at the browser level before it’s encrypted.
A browser agent isn’t just a proxy for pre-TLS HTML data, though. In the browser, you’re able to dynamically interact with the DOM or the rendered web application, including its JS code. This makes it easy to find, for example, input fields for usernames and passwords. You can see what information the user is inputting and where, without needing to figure out how the data is encoded and sent back to the app. These are fairly generic fields that can be identified across your suite of apps without needing complex custom code. To put it in perspective, approximately 10 login cases cover the entirety of the SaaS apps we support (~1000). Using a proxy-based solution, each of these would require custom development.
While it's technically possible to keep track of multiple sessions for thousands of users across hundreds of apps via proxy, it’s no mean feat – made much easier when each extension is tracking one user, in one browser, and even knows the browser tab it’s running in. You also get additional context at the identity layer such as the email address, authentication protocol, and credentials used, neatly mapped to that specific user and browser profile – no more trying to link the owner of an IP address to log events!
The browser also has the added benefit of being a natural enforcement point. You can collect and analyze data dynamically, and produce an immediate response – rather than taking info away, analyzing it, and coming back with a detection minutes or hours later (and potentially prompting a manual response).
Let’s look at a couple of examples based on how we’re using our browser agent to detect and block identity attacks.
Pinning passwords to the legitimate site they are linked with. This is made possible by interacting with the DOM to observe passwords being entered – enabling the Push agent to intercept and block before an HTTP network request can even be made.
Detecting and blocking malicious phishing tools running on websites by observing behavioral attributes in the browser, such as Javascript calls being made or data structures saved to local storage.
Observing users signing up to and using risky apps, or changing or removing authentication methods, MFA methods, and configuration methods, which could indicate account takeover.
It’s always useful to refer back to the concept of the Pyramid of Pain in these situations. The opportunities to detect and block in the browser tend to align with indicators at the apex of the pyramid, meaning they are a significant obstruction for attackers – and difficult to circumvent. This contrasts the indicators aligned with proxy-based solutions, which are much easier to bypass through, for example, IP masking using residential proxy networks, or changing the domains and URLs used for phishing campaigns.
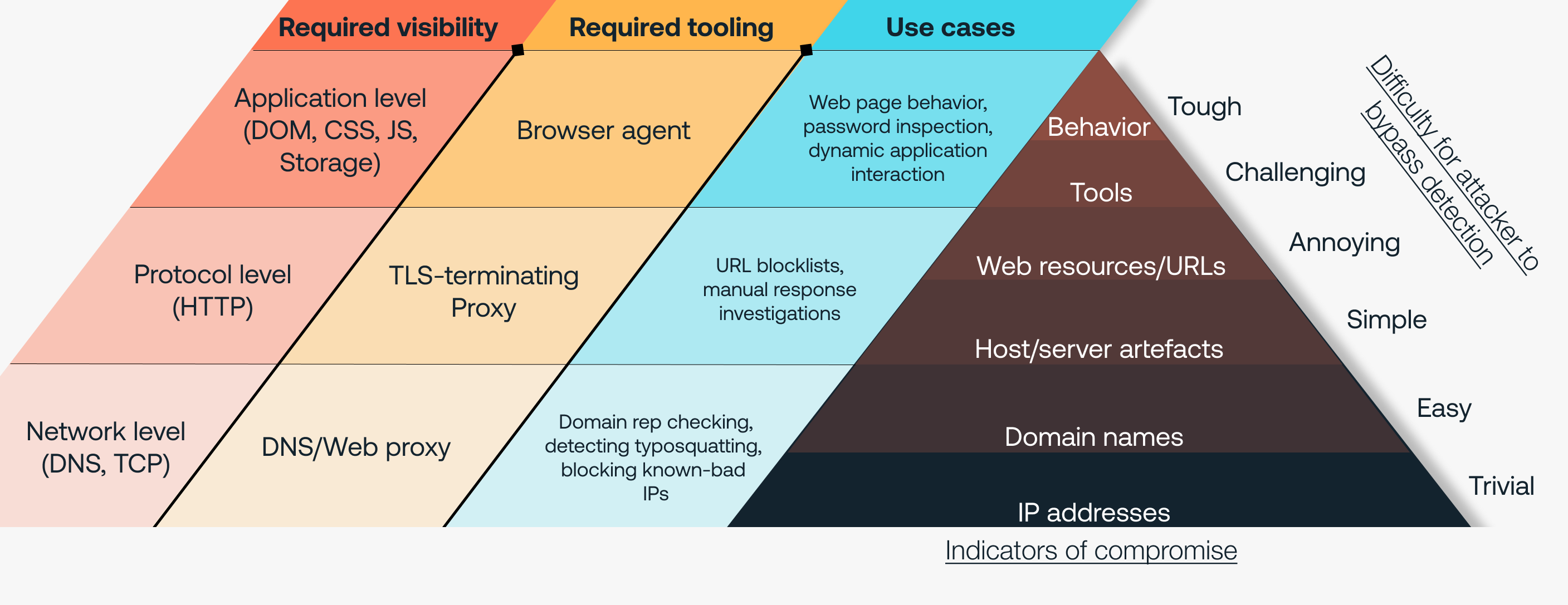
In summary: Browser data provides high-fidelity indicators of malicious activity, without the complications of proxy-based approaches. The scope for response in the browser is significant and immediate, meaning it’s a great enforcement point for security controls to be able to disrupt attacks.
Won’t my app and IdP logs cover this?
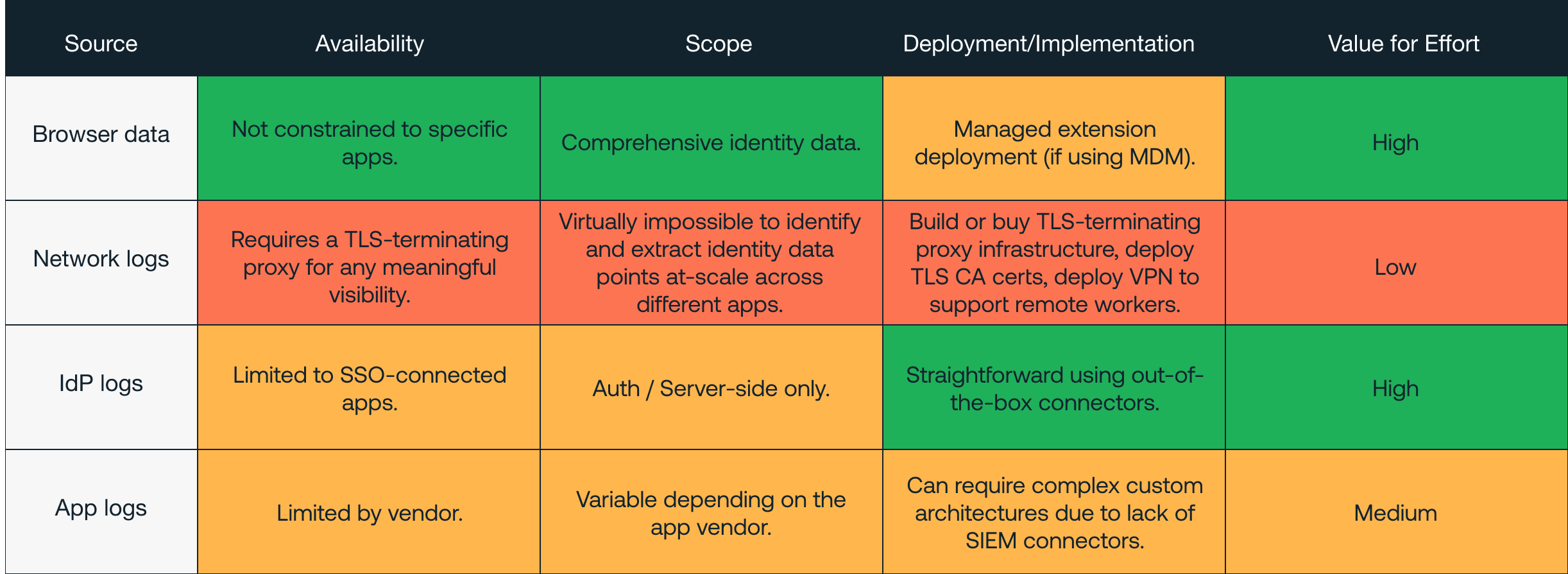
App and IdP logs are useful (when you can get them), but neither give you the full picture.
App logs are limited in availability, scope, and ease of ingestion
When relying on app logs, you’re naturally constrained by the app provider. Many smaller apps provide no security logging, while others lock security logging behind the premium tier subscription. When logs are available, you’re limited to the events that the third-party deems suitable to log.
Out of the 100 most popular apps we see across our customers, and perhaps the few dozen or so that are security critical, only a small handful provide any useful logging. This means, naturally, that the majority of apps do not.
To top it all off, the process of extracting these logs and feeding them into your SIEM (or equivalent) is also not straightforward. The lack of out-of-the-box connectors for many apps means that complex custom architectures are required for collecting data. Some vendors place constraints on the format and mechanism for extracting logs which can make ingestion difficult to feed reliable detections – even before any meaningful analysis of the data can take place.
Until application security logs are made widely available (and at no additional cost) it’s unlikely you’re going to be able to get the visibility you need from app logs, for every app your employees use (though of course there are exceptions – and we hope to see more vendors in future treating security as a minimum requirement, not a chargeable addon).
IdP logs cover only SSO integrated apps and are limited in scope
You might think, “but all of our business apps are behind SSO, right?” In reality, only about 1 in 3 apps support SSO (and even fewer at the ‘free’ tier). And in practice, our data shows us that only 1 in 5 apps on average are actually behind SSO per organization. The theoretical security benefit of IdP logs is that they provide context, a foundation for the user’s activity across (and between) a suite of apps. But because of the lack of coverage, this isn’t the case.
IdP logs are naturally focused on authentication, and so don’t compensate for any gaps in app logging. Naturally, they are only able to observe what happens on the IdP side – and so are blind to client side attacks like phishing (which we’ve already shown the browser provides superior visibility of compared to typical alternatives like proxy logs).
Browser is best for stopping identity attacks
This is where the browser comes in. Think of your browser as your source of truth, a broad data baseline for user activity where the browser provides complete context of the browser profile, employee, accounts, credentials, auth methods, and MFA types – as well as employee interaction with web sites.
The TL;DR is that your visibility in the browser is theoretically limitless. Every page loaded (and its source, javascript state, local storage), every user interaction can be observed. And best of all, this analysis is done securely in the browser and only the results of detections are reported back, rather than decrypting the entire raw traffic stream including all session data in an additional centralized system.
Conclusion
As an industry, we need to start looking at browser-based detection and response as the next logical evolution to stop identity attacks. There are clear parallels with the emergence of EDR – which came about because existing endpoint log sources were not sufficient. Today, we wouldn’t dream of trying to detect and respond to endpoint-based attacks without EDR – it’s time we started thinking about cloud identity attacks and the browser in the same way.
